









ChessBase 17 - Mega package - Edition 2024
It is the program of choice for anyone who loves the game and wants to know more about it. Start your personal success story with ChessBase and enjoy the game even more.
The core essence of the ICGA’s case against Rajlich is that Rybka and Fruit have very similar positional evaluations, i.e. a chess program’s mathematical assessment of which side is winning in a given position. Dr. Hyatt announces in the Rybka forum that he is so confident that Rajlich has been so completely and redundantly busted in this area that no further analysis is needed:
I suppose one could have gone into every bit and piece of Rybka to see what was original and what was copied, but after the evaluation study, there seemed to be little justification for the effort required...
The problem is that the ICGA’s findings on the evaluation similarities between Fruit and Rybka tend to fall into one of these three descriptions.
I’ll go over some of the ICGA’s specific charges in due course, but first it is important to itemize the significant ways Rybka’s evaluation differs from Fruit’s.
The first big evaluation difference between the programs is that they are grounded on different valuation conventions. Fruit's evaluation is based on a programming tradition going back decades which stipulates that a pawn is worth 1.00. From its initial release Rybka’s evaluation was based not on piece values but projected winning percentages. Per Rajlich, this mathematically subtle difference plays a significant role in testing.
Ed Schröder reveals five additional major differences versus Fruit in his investigations:
“Lazy” evaluation is not in Fruit but is present in Rybka.
The programs have entirely different futility pruning approaches.
Fruit has only one evaluation array related to King Safety. Rybka has many.
The Fruit "quad" function calculates a value based on the rank of a passed pawn in an unusual way, using up valuable processor time when this can be done in just one instruction via a PST or rank-based table, as is done in Rybka and many other programs.
Fruit evaluates in two steps, while Rybka directly adds up an evaluation score.
That makes six differences altogether: differences that are actually substantial and impact playing strength, unlike some of the tangential issues discussed in the ICGA report. But next Rajlich points out four more big differences in this illuminating passage:
Fabien was a big search guy who basically didn't care about eval, but he nevertheless really hit on a major point with his eval. His eval was based completely on mobility. This has two nice properties. The first is that it interacts well with the search – having the right to make more moves tends to coincide with the chances that more searching will improve the score. The second is that it's symmetrical and continuous, because all pieces are basically handled in a similar way. Every piece has the right to move to certain squares. This symmetry is elegant, eliminates discontinuities, makes the eval smooth, helps with tuning, etc.
Re. Rybka 1.0 Beta vs Fruit 2.1 eval – I don't know the exact differences. There must be a lot of little things. Generally I would say that Rybka 1.0 Beta had the following big eval innovations:
Material imbalances – Rybka was the first engine to understand that major pieces are more valuable in endgames. See for example the game Ikarus-Rybka from Paderborn 2005 – every engine except for Rybka thought that white was much better in that NN vs RP endgame, while any decent player would know that black is perfectly fine.
Passed pawns – passers are the other major exception to mobility based evaluation. Rybka 1.0 Beta had quite a few heuristics for scoring passers, I am quite sure again that these are far ahead of Fruit or other engines from 2005.
Tuning – I had my own eval tuner which was kind of primitive compared to what I have now, but nevertheless I think that it was better than what Fabien and others had in 2005.
These are worth maybe 20 Elo each.
One other unusual feature of Rybka's eval from that time is that I tried to have as few correlated eval terms as possible. I took this pretty far. For example Rybka didn't score doubled pawns (I'm not sure about the exact versions but I think this applies to Rybka 1.0 Beta). A doubled pawn penalty is mostly redundant with penalties for a weakened king shelter or for the inability to create a passed pawn, so Rybka would only score the underlying issues (i.e. the king shelter and passed pawn creation). I later decided that this was wrong, but anyway it's a unique feature of Rybka's eval from 2005.

The ten substantive evaluation differences outlined above, combined with Rybka’s entirely different search and board representation, signify that Rybka and Fruit must be considered two different chess engines by any reasonable person. These differences go a considerable distance to explain why, per every independent rating group, the 64-bit version of Rybka 1.0 Beta played some 150+ Elo points stronger than Fruit 2.1 (which only came in a 32-bit version).
We can see that Rajlich’s evaluation was materially different from Letouzey’s in at least ten ways, but how did he develop these ideas? We find our answer in new information about Rajlich’s early programming R&D work. During 2004 and 2005 Rajlich wrote himself a series of notes, some of substantial length, on evaluation. He kindly emailed me some of these notes which make it amply clear that he was intellectually engaged in evaluation and that copying was the furthest thing from his mind.
These files were written in the same period that his accusers claim he spent feverishly copying Fruit’s evaluation. It is exceedingly hard to see the point of developing a slew of original ideas for Rybka only then to copy Fruit’s evaluation.

There is another difference between Rybka and Fruit that merits comment. A common misperception following the ICGA’s report was that Rybka transcribed Fruit’s evaluation practically verbatim into a different board representation, and was principally different from Fruit in “the search” (i.e. algorithms related to searching for the best move). As we have already seen, the idea that Rybka’s evaluation is the same as Fruit’s is totally wrong both in the specifics and the underlying premise.
To further clarify this point, Fruit used a “mail-box” representation of the chessboard, while Rybka used a “bit-board” representation. How a chessboard is represented in a program has nothing to do with evaluation; it is purely a difference in program architecture. Rajlich dismisses the importance of chessboard representation with this comment:
If you take Fruit’s evaluation and modify it from Fruit’s board representation (called mail-box) to Rybka’s board representation (called bit-board) no serious Elo difference is expected except possibly slightly lower Elo on 32-bit processors and slightly higher Elo on 64-bit processors.
Given the points I’ve outlined above what are we to make of the following categorical statements made by Zach Wegner in his ICGA report findings?
Simply put, Rybka's evaluation is virtually identical to Fruit's
Overall, the pawn evaluations of each program are essentially identical.
Because of Fruit's unique PST initialization code, the origin of Rybka's PSTs in Fruit is clear.
These are all demonstrably incorrect and tendentious conclusions which would be extremely misleading to someone who lacked the requisite technical expertise or was not prepared to invest the necessary time to study the full contents of his paper.
Mark Watkins, in his analysis of Rybka-Fruit similarities, compares several chess engines with respect to their evaluation “features” and shows that Rybka 1.0 Beta has an “eval feature overlap” with Fruit 2.1 of about 74% (Rybka 2.3.2a is judged to be about 64%).
Watkins shows “feature overlap”, not a “code overlap”. The precise definition of an evaluation term in a chess engine (e.g. “rook on the seventh rank”) is a mathematical formula which is calculated by an algorithm. The algorithm itself is an abstract concept. It is implemented in a programming language based on explicit data structures defined by the surrounding program – that is called “code”. But Watkins’ evaluation feature is in actuality the formula expressed by an algorithm. This formula is on the conceptual level and therefore, according to accepted practice, everyone is free to use it. Thus his entire analysis lacks traction.
But there are a few points that ought to be made about his analysis. First, his choice of engines to compare against Rybka and Fruit are relatively weak, and this fact puts the practical value of their evaluation feature set in comparison to world-class engines under question.
Next, it should be mentioned that the assignment of “feature overlap” values for each single evaluation term, using a scale of 0.0 to 1.0, was based on inherently subjective judgments. Given Watkins’ analysis template, if we were to ask a group of programming experts to assign overlap values to the engine pairs under question, one cannot be sure how close Watkins’ values would be to the average values they assigned, let alone how closely his values would correspond to practical reality, which in any event is impossible to calculate with precision.
Finally, there is the matter of data interpretation. Even if we ignore the points cited above, questions must be raised. Why is an overlap value in the range of 40%-44% “allowed” but a value of 64% (Rybka 2.3.2a vs. Fruit) or 74% (Rybka 1.0 Beta vs. Fruit) “not allowed”? Who sets these standards and what are they based upon? Can the ICGA create and enforce new standards years after a tournament is completed?
A source of strife since the ICGA issued its report has been an analysis of Rybka’s time management code. All chess engines have to ration how long they can spend thinking about a move based in part on how much time they have left on the chess clock. Time management, obviously, is as important in computer chess as it is in human chess, particularly in situations when time remaining is down to a few seconds.
Ironically, the basis of the ICGA’s argument boils down to an interpretation of one line of source code in Rybka 1.0 Beta which they believe contains ‘0.0’. (No joke, ‘0.0’ appearing in a program written in 2005 has been a major issue for the ICGA investigators.)
Fruit used a system of floating point numbers or “floats” (such as “0.0”) for managing its time. Rybka 1.0 Beta had a faster and simpler approach using integers (such as “0”) for checking time.
There is a time check within Rybka 1.0 Beta that the ICGA investigation team says looks like this:
If (movetime >= 0.0)
There is a time check in Fruit the looks like this:
If (movetime >= 0.0)
So the ICGA investigators argued the following:
Rybka uses integer based time management so we would expect Rybka to look like this:
If (movetime >= 0)
The fact that Rybka does not utilize an integer format, and instead uses a floating point convention just like Fruit, is undeniable proof that code-copying occurred.
I asked Rajlich how the ‘0.0’ might have happened in Rybka and this was his response:
I don’t know where the 0.0 came from. It’s definitely weird/wrong. Rybka was UCI from the beginning, even back when everybody was using WinBoard. I would say that every two to three years I do a big cleanup of this code. This might take a few hours, and then I won’t touch it until the next time. My first UCI parser actually used inheritance, I was extending UCI to do some testing, but that was gone even before Rybka 1.
This entire line of argument started years ago on Talkchess with a post by Rick Fadden, wherein he pointed out the floating-point versus integer format mismatch. This observation, which I have no reason to think was not made in good faith, was probably the public origin of the Rajlich controversy. I say this because this piece of seemingly concrete evidence placed into the psyches of rival chess programmers that Rajlich must have copied code from Fruit, and once that was accomplished all that was needed was someone like Fabien Letouzey to return from computer chess retirement to light the fuse.
But here’s the thing: Fadden assumed that Rajlich really typed or copied ‘0.0’. It is quite possible that his assumption was incorrect. Remember, Fadden didn’t have Rajlich’s original source code either; his output only indicated that something extraneous to integer format was on that line of code.
Rajlich could have typed this instead:
If (movetime >= 0.)
In other words, he could have just added a dot to the zero. If he did, this would have compiled to exactly the same floating point compare instructions as if ‘0.0’ had been coded.
The technical experts who helped me write this paper could scarcely believe this point when it first dawned on them. They researched and double-checked, and found that on Microsoft compilers contemporaneous with 2005 this observation is indisputably correct.
The truth of the matter is that there is no definitive and provable answer. I came to the conclusion that ‘0.0‘ is a litmus test. If you believe that Rajlich is guilty of code-copying then ‘0.0’ reinforces that belief and is your smoking gun. If you believe that Rajlich is innocent then you are apt to conclude that typing ‘0.‘ (not ‘0.0’) was a simple coding oversight. Further mitigating circumstances I can offer to those in the guilty camp are these:
Time management is not “game-playing code” (per ICGA Rule 2). It is interface code from the engine to the outside world, i.e. Rajlich’s reference to a “UCI parser”.
Comparing the UCI parameters for the two engines reveals they are markedly different just as we saw with the comparison of Rybka and Fruit evaluations. Fruit 2.1 has twenty configurable UCI parameters (hash-size not shown in the figure below). Rybka 1.0 Beta, in contrast, has only two such parameters.
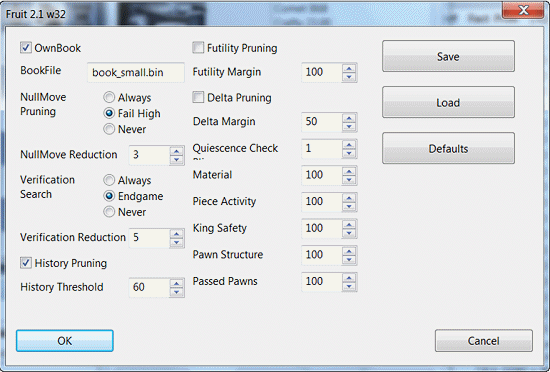

But ultimately the “big picture” argument is the most compelling. This contentious ‘0.0’ issue comes down to a dispute about one extra keystroke, one single dot, on one line of code that has zero impact on how the program actually plays. On what reasonable basis can a person conclude from this one superfluous dot that Rybka is non-original and Rajlich deserves to have all his titles stripped and be banned for life? How could this literally nugatory piece of evidence tip the scales in favor of the prosecution? How many devils can dance on a dot of code?
To Part four...
Thanks to Ed Schröder for encouraging me to write this article as well as his insights on the computer chess scene going back decades. A special thanks to Nelson Hernandez, Nick Carlin, Chris Whittington, Sven Schüle and Alan Sassler for their first class editing as well as their many valuable suggestions. Without the lively collaboration of these individuals spanning several weeks this paper could not have been written. Finally, let me thank Vasik Rajlich for his clarification of various technical points and contemporaneous notes.
Thanks also to Dann Corbit, Miguel Ballicora, Rasmus Lerchedahl Petersen, Cock de Gorter, Jiri Dufek for their excellent suggestions and eagle-eyed proof reading.

Søren Riis is a Computer Scientist at Queen Mary University of London. He has a
PhD in Maths from University of Oxford. He used to play competitive chess (Elo 2300).
 |
A Gross Miscarriage of Justice in Computer Chess (part one) 02.01.2012 – "Biggest Sporting Scandal since Ben Johnson" and "Czech Mate, Mr. Cheat" – these were headlines in newspapers around the world six months ago. The International Computer Games Association had disqualified star programmer Vasik Rajlich for plagiarism, retroactively stripped him of all titles, and banned him for life. Søren Riis, a computer scientist from London, has investigated the scandal. |
 |
A Gross Miscarriage of Justice in Computer Chess (part two) 03.01.2012 – In this part Dr Søren Riis of Queen Mary University in London shows how most programs (legally) profited from Fruit, and subsequently much more so from the (illegally) reverse engineered Rybka. Yet it is Vasik Rajlich who was investigated, found guilty of plagiarism, banned for life, stripped of his titles, and vilified in the international press – for a five-year-old alleged tournament rule violation. Ironic. |













